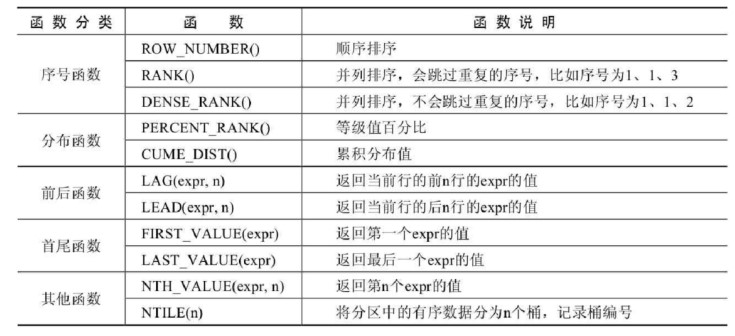
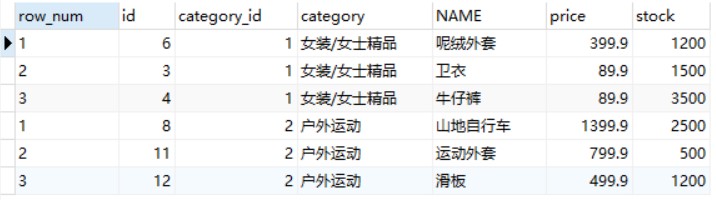
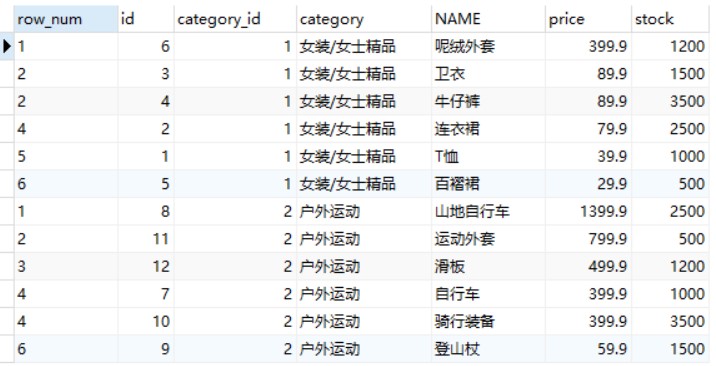
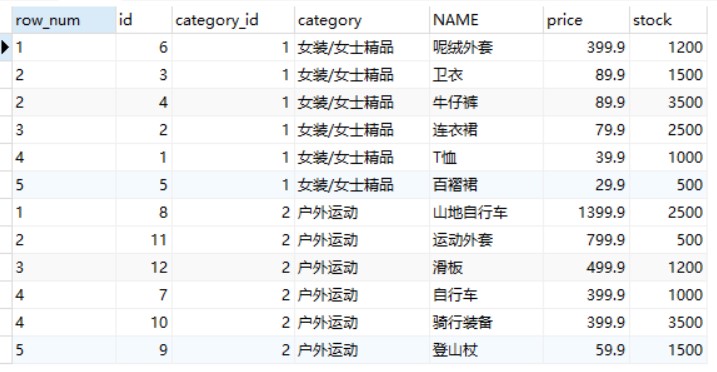
-- 使用DENSE_RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息 SELECTDENSE_RANK() OVER(PARTITIONBY category_id ORDERBY price DESC) AS row_num, id, category_id, category, NAME, price, stock FROM goods;
1 2 3 4 5 6
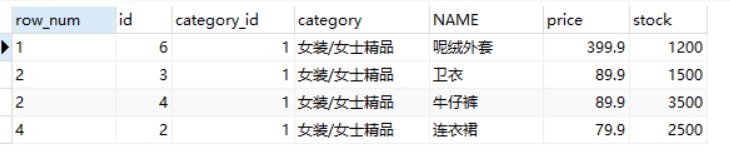
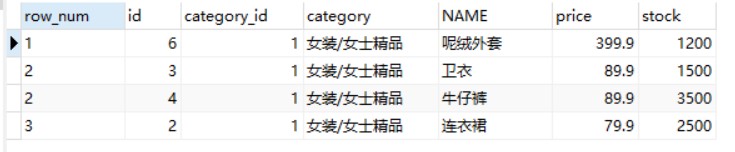
-- 使用DENSE_RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息 SELECT* FROM( SELECTDENSE_RANK() OVER(PARTITIONBY category_id ORDERBY price DESC) AS row_num, id, category_id, category, NAME, price, stock FROM goods) t WHERE category_id =1AND row_num <=3;
分布函数
PERCENT_RANK()函数
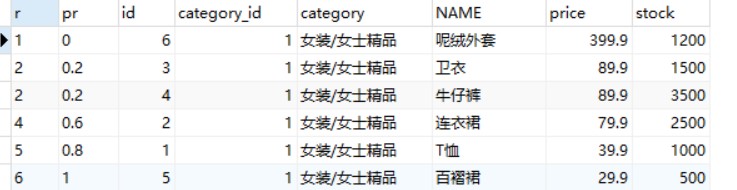
PERCENT_RANK()函数是等级值百分比函数。按照如下方式进行计算。
其中,rank的值为使用RANK()函数产生的序号,rows的值为当前窗口的总记录数
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-- 计算 goods 数据表中名称为“女装/女士精品”的类别下的商品的PERCENT_RANK值 -- 写法1 SELECTRANK() OVER (PARTITIONBY category_id ORDERBY price DESC) AS r, PERCENT_RANK() OVER (PARTITIONBY category_id ORDERBY price DESC) AS pr, id, category_id, category, NAME, price, stock FROM goods WHERE category_id =1;
-- 写法2 SELECTRANK() OVER w AS r, PERCENT_RANK() OVER w AS pr, id, category_id, category, NAME, price, stock FROM goods WHERE category_id =1WINDOW w AS (PARTITIONBY category_id ORDERBY price DESC);
CUME_DIST()函数
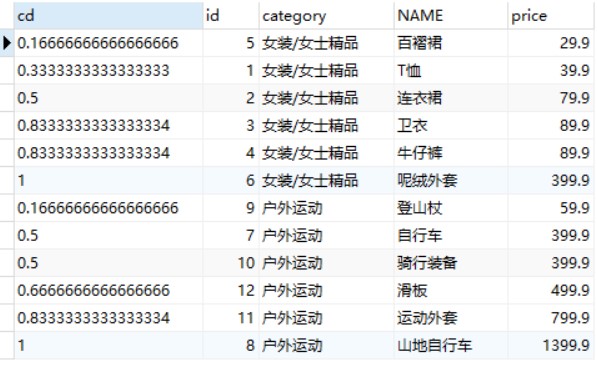
CUME_DIST()函数主要用于查询小于或等于某个值的比例。
1 2 3
-- 查询goods数据表中小于或等于当前价格的比例 SELECTCUME_DIST() OVER(PARTITIONBY category_id ORDERBY price ASC) AS cd, id, category, NAME, price FROM goods;
前后函数
LAG(expr,n) 函数
LAG(expr,n)函数返回当前行的前n行的expr的值。
1 2 3 4 5 6
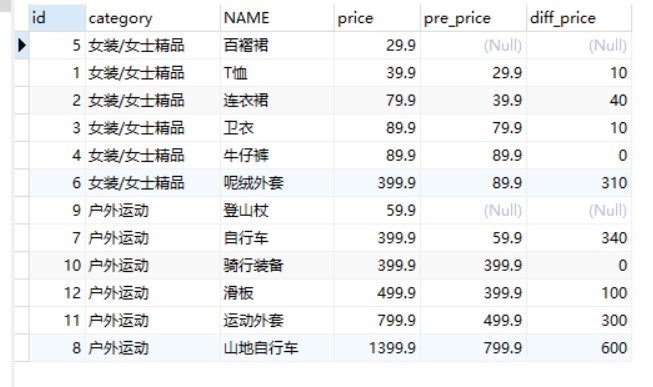
-- 查询goods数据表中前一个商品价格与当前商品价格的差值 SELECT id, category, NAME, price, pre_price, price - pre_price AS diff_price FROM ( SELECT id, category, NAME, price,LAG(price,1) OVER w AS pre_price FROM goods WINDOW w AS (PARTITIONBY category_id ORDERBY price)) t;
LEAD(expr,n)函数
LEAD(expr,n)函数返回当前行的后n行的expr的值
1 2 3 4 5
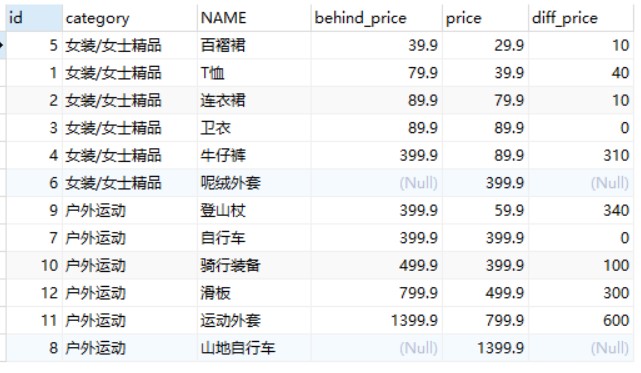
-- 查询goods数据表中后一个商品价格与当前商品价格的差值 SELECT id, category, NAME, behind_price, price,behind_price - price AS diff_price FROM( SELECT id, category, NAME, price,LEAD(price, 1) OVER w AS behind_price FROM goods WINDOW w AS (PARTITIONBY category_id ORDERBY price)) t;
首尾函数
FIRST_VALUE(expr)函数
FIRST_VALUE(expr)函数返回第一个expr的值。
1 2 3
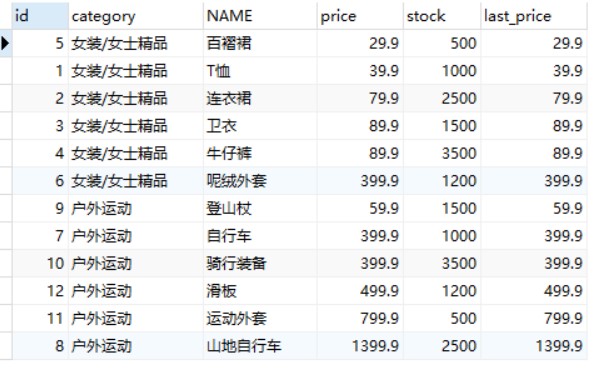
-- 按照价格排序,查询第1个商品的价格信息 SELECT id, category, NAME, price, stock,FIRST_VALUE(price) OVER w AS first_price FROM goods WINDOW w AS (PARTITIONBY category_id ORDERBY price);
LAST_VALUE(expr)函数
LAST_VALUE(expr)函数返回最后一个expr的值。
1 2 3
-- 按照价格排序,查询最后一个商品的价格信息 SELECT id, category, NAME, price, stock,LAST_VALUE(price) OVER w AS last_price FROM goods WINDOW w AS (PARTITIONBY category_id ORDERBY price);
其他函数
NTH_VALUE(expr,n)函数
NTH_VALUE(expr,n)函数返回第n个expr的值。
1 2 3
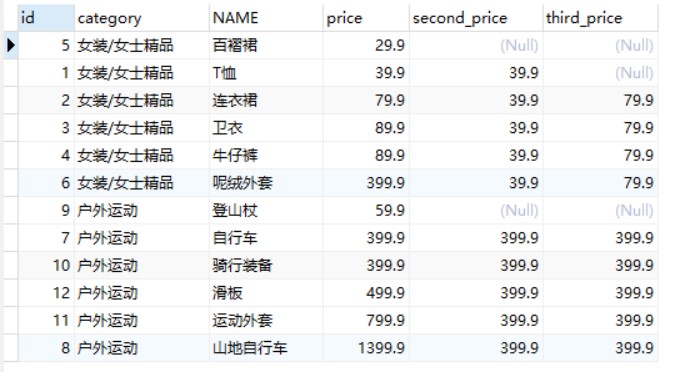
-- 查询goods数据表中排名第2和第3的价格信息 SELECT id, category, NAME, price,NTH_VALUE(price,2) OVER w AS second_price, NTH_VALUE(price,3) OVER w AS third_price FROM goods WINDOW w AS (PARTITIONBY category_id ORDERBY price);
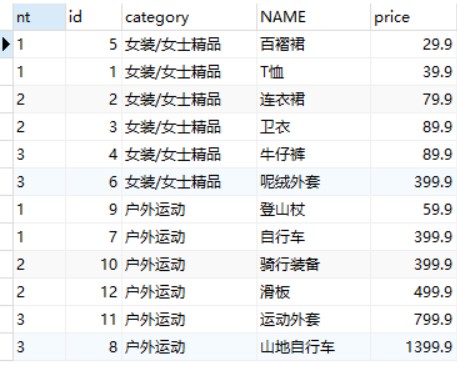
NTILE(n)函数
NTILE(n)函数将分区中的有序数据分为n个桶,记录桶编号
1 2 3
-- 将goods表中的商品按照价格分为3组 SELECTNTILE(3) OVER w AS nt,id, category, NAME, price FROM goods WINDOW w AS (PARTITIONBY category_id ORDERBY price);
SELECT s.city AS 城市,s.county AS 区,s.sales_value AS 区销售额 b.sales_value AS 市销售额,s.sales_value/b.sales_value AS 市比率, a.sales_value AS 总销售额,s.sales_value/a.sales_value AS 总比率 FROM sales s JOIN b ON (s.city=b.city) -- 连接市统计结果临时表 JOIN a -- 连接总计金额临时表 ORDERBY s.city,s.county;
SELECT city AS 城市,county AS 区,sales_value AS 区销售额, SUM(sales_value) OVER(PARTITIONBY city) AS 市销售额, -- 计算市销售额 sales_value/SUM(sales_value) OVER(PARTITIONBY city) AS 市比率, SUM(sales_value) OVER() AS 总销售额, -- 计算总销售额 sales_value/SUM(sales_value) OVER() AS 总比率 FROM sales ORDERBY city,county;
WITHRECURSIVE cte AS ( SELECT employee_id,last_name,manager_id,1AS n FROM employees WHERE employee_id =100 -- 种子查询,找到第一代领导 UNIONALL SELECT a.employee_id,a.last_name,a.manager_id,n+1FROM employees AS a JOIN cte ON (a.manager_id = cte.employee_id) -- 递归查询,找出以递归公用表表达式的人为领导的人 ) SELECT employee_id,last_name FROM cte WHERE n >=3;