
算法提升-1-哈希表与哈希函数
自定义结构 RandomPool
请设计出一种结构,在该结构中有如下三个功能,要求其时间复杂度为 $O(1)$
insert(key):将某个 key 加入到该结构,做到不重复加入delete(key):将原本在结构中的某个 key 移除getRandom(): 等概率随机返回结构中的任何一个key
设计思路
设计两个哈希表
keyIndexMap和indexKeyMapkeyIndexMap用来记录 key 到 index 的对应关系indexKeyMap用来记录 index 到 key 的对应关系整数size初始化为0,记录Pool的大小
执行
insert(newKey),将(newKey,size)放入keyIndexMap,将(size,newKey)放入indexKeyMap,然后size自增执行
delete(deleteKey),最新加入的key记为lastKey,对应的index信息记为lastIndex。删除的key记为deleteKey,对应的index记为deleteKey- 把记录(lastKey,lastIndex)变为(lastKey,deleteIndex),并在indexMap中把记录(deleteIndex,deleteKey)变为(deleteIndex,lastKey)
- 在keyIndexMap中删除记录(deleteKey,deleteIndex),在indexKeyMap中把记录(lastIndex,lastKey)删除
- size减一
getRandom操作时根据size随机得到index,返回对应的key


1 | public class RandomPool { |
bitmap
基本思想:用一个bit位标记某个元素对应的value,key即是该元素
假设32位操作系统,4G内存,在20亿个随机整数中找出某个数m是否存在其中
如果每个数字用int存储,那就是20亿个int,因而占用的空间约为 (20000000004/1024/1024/1024)≈ *7.45 G
如果每个数字用位存储,20亿的数就是20亿位,占空间约为(2000000000/8/1024/1024/1024)≈ 0.23 G
存储数据
用bitmap存储(1, 2 ,4, 6)

1个int占32位,那么我们只需要申请一个int数组长度为 int tmp[1+N/32] 即可存储,其中N表示要存储的这些数中的最大值,于是乎:
tmp[0]:可以表示0~31
tmp[1]:可以表示32~63
tmp[2]:可以表示64~95
添加操作
放入数字5,5/32=0,5%32=5,在temp[0]位置,把1向左移动五位,按位或
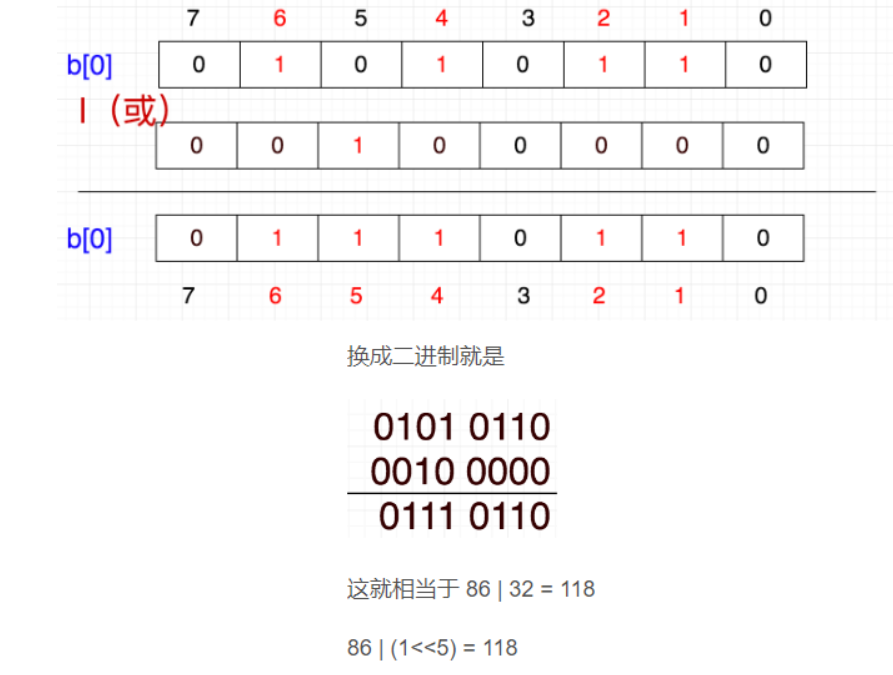
b[0] = b[0] | (1<<5)
插入一个数,将1左移带代表该数字的那一位,然后与原数进行按位或操作
公式可以概括为:p + (i/8)|(1<<(i%8)) 其中,p表示现在的值,i表示待插入的数
删除操作
删除6

1左移6位,到达数字6代表的位,然后按位取反,最后与原数按位与
b[0] = b[0] & (~(1<<6))
b[0] = b[0] & (~(1<<(i%8)))
查找操作
判断3在不在,那么只需判断 b[0] & (1<<3) 如果这个值是0,则不存在,如果是1,就表示存在
1 |
|
应用场景
优缺点
优点:
- 运算效率高,不需要进行比较和移位;
- 占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M
缺点:
- 所有的数据不能重复。即不可对重复的数据进行排序和查找。
- 只有当数据比较密集时才有优势
快速排序
要对0-7内的5个元素
(4,7,2,5,3)排序(这里假设这些元素没有重复)要表示8个数,我们就只需要8个Bit(1Bytes),开辟1Byte的空间,将这些空间的所有Bit位都置为0,然后将对应位置为1。
遍历一遍Bit区域,将该位是一的位的编号输出
(2,3,4,5,7),这样就达到了排序的目的,时间复杂度 $O(n)$
快速去重
20亿个整数中找出不重复的整数的个数,内存不足以容纳这20亿个整数
一个数字的状态只有三种,分别为不存在,只有一个,有重复。
需要2bit就可以对一个数字的状态进行存储
假设一个数字不存在为
00,存在一次01,存在两次及其以上为11。那我们大概需要存储空间2G左右。把这20亿个数字存储,如果对应的状态位为
00,则将其变为01,表示存在一次如果对应的状态位为
01,则将其变为11,表示已经有一个了,即出现多次如果为
11,则对应的状态位保持不变,仍表示出现多次统计状态位为
01的个数,就得到了不重复的数字个数,时间复杂度为 $O(n)$
快速查找
int数组中的一个元素是4字节占32位,那么除以32就知道元素的下标,对32求余数(%32)就知道它在哪一位,如果该位是1,则表示存在
补充:在没有溢出的前提下
<<左移,相当于乘以2的n次方,例如:1<<6 相当于1×64=64,3<<4 相当于3×16=48*>>右移,相当于除以2的n次方,例如:64>>3 相当于64÷8=8^异或,相当于求余数,例如:48^32 相当于 48%32=16
总结回顾
Bitmap主要用于快速检索关键字状态,通常要求关键字是一个连续的序列(或者关键字是一个连续序列中的大部分)
最基本的情况,使用1bit表示一个关键字的状态(可标示两种状态),但根据需要也可以使用2bit(表示4种状态),3bit(表示8种状态)。
Bitmap的主要应用场合:表示连续(或接近连续,即大部分会出现)的关键字序列的状态(状态数/关键字个数 越小越好)
布隆过滤器
突破口
面试遇到黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统等。又看到系统容忍一定程度的失误率,但是对空间要求严格,可以考虑布隆过滤器
布隆过滤器是一个很长的二进制向量和一系列随机映射函数。一个布隆过滤器精确的代表一个集合,可以精确判断一个元素是否在一个集合中,缺点是有一定的误识别率和删除困难。
布隆过滤器
布隆过滤器的优点:
时间复杂度低,增加和查询元素的时间复杂为 $O(N)$ ,( $N$ 为哈希函数的个数,通常情况比较小)
保密性强,布隆过滤器不存储元素本身
存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
布隆过滤器的缺点:
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
应用场景
布隆过滤器可以告诉我们 “某样东西一定不存在或者可能存在”,也就是说布隆过滤器说这个数不存在则一定不存在,布隆过滤器说这个数存在可能不存在
解决Redis缓存穿透问题
邮件过滤,使用布隆过滤器来做邮件黑名单过滤
对爬虫网址进行过滤,爬过的不再爬
解决新闻推荐过的不再推荐(类似抖音刷过的往下滑动不再刷到)
HBase\RocksDB\LevelDB等数据库内置布隆过滤器,用于判断数据是否存在,可以减少数据库的IO请求
实现原理
当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组(Bit array)中的 K 个点,把它们置为 1 。
检索时,只要看看这些点是不是都是1就知道元素是否在集合中;如果这些点有任何一个 0,则被检元素一定不在;如果都是1,则被检元素很可能在(之所以说“可能”是误差的存在)。
数据结构
布隆过滤器是一个很长的二进制向量和一系列随机映射函数
以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是 一个大型位数组(二进制数组)+ 多个无偏hash函数
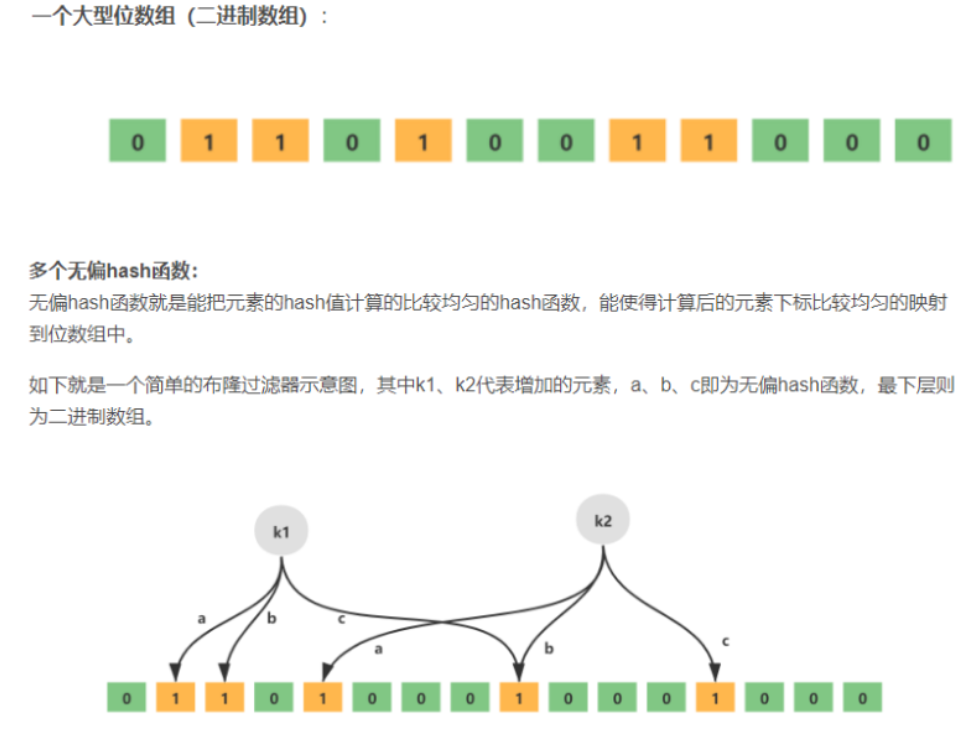
空间计算
在布隆过滤器增加元素之前
- 需要初始化布隆过滤器的空间,也就是上面说的二进制数组
- 需要计算无偏hash函数的个数。
布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。
布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。
它们之间的关系比较简单:
- 错误率越低,位数组越长,控件占用较大
- 错误率越低,无偏hash函数越多,计算耗时较长
增加元素
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,
然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 将计算得到的数组索引下标位置数据修改为
1
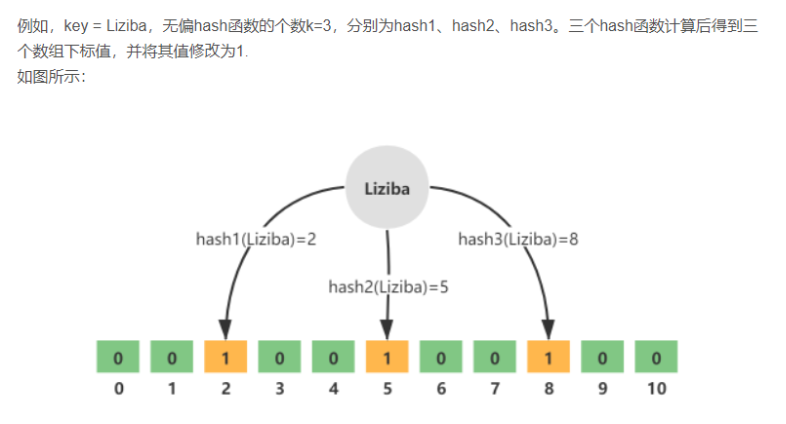
查询元素
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 判断索引处的值是否全部为1,如果全部为1则存在==(这种存在可能是误判)==,如果存在一个0则必定不存在
关于误判,其实非常好理解,hash函数在怎么好,也无法完全避免hash冲突,也就是说可能会存在多个元素计算的hash值是相同的,那么它们取模数组长度后的到的数组索引也是相同的,这就是误判的原因。
例如李子捌和李子柒的hash值取模后得到的数组索引都是1,但其实这里只有李子捌,如果此时判断李子柒在不在这里,误判就出现啦!

一致性哈希算法
问题背景
工程师使用服务器集群设计和实现数据缓存
1.无论是添加、查询和删除数据,都先将数据的id通过哈希函数转换成哈希值,记为key
2.如果目前机器有N台,则计算key%N的值,这个值就是该数据所属的机器编号,无论添加、删除还是查询,都只在这台机器上运行
该缓存策略存在的问题
如果增加或删除机器,所有的数据不得不根据id重新算哈希值,并将哈希值对新机器数进行取模操作,然后进行大规模数据迁移
改进方案
分布式系统中对象与节点的映射关系,传统方案是使用对象的哈希值,对节点个数取模,再映射到相应编号的节点,
这种方案在节点个数变动时,绝大多数对象的映射关系会失效而需要迁移
而一致性哈希算法中,当节点个数变动时,映射关系失效的对象非常少,迁移成本也非常小。
算法原理
映射方案

公用哈希函数和哈希环
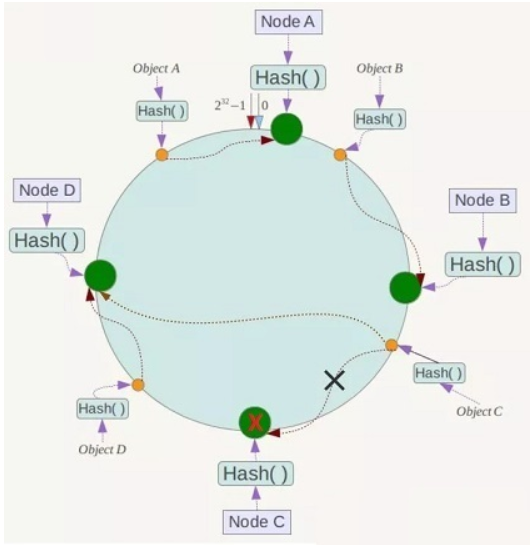
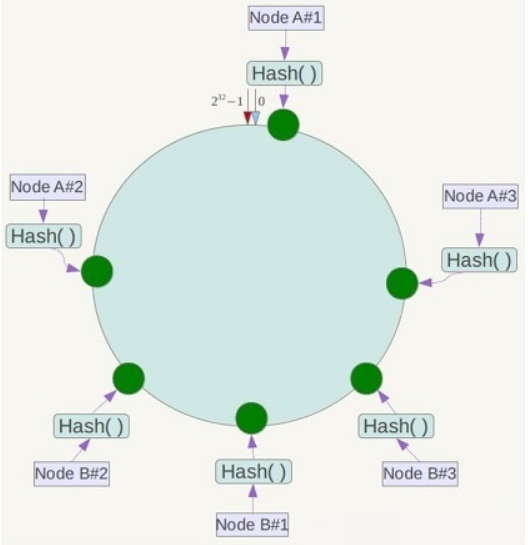
设计哈希函数 Hash(key),要求取值范围为 $[0, 2^{32})$
各哈希值在上图 Hash 环上的分布:时钟12点位置为0,按顺时针方向递增,临近12点的左侧位置为 $2^{32}-1$ 。
节点(Node)映射至哈希环
如图哈希环上的绿球所示,四个节点 Node A/B/C/D,其 IP 地址或机器名,经过同一个 Hash() 计算的结果,映射到哈希环上。
对象(Object)映射至哈希环
如图哈希环上的黄球所示,四个对象 Object A/B/C/D,其键值,经过同一个 Hash() 计算的结果,映射到哈希环上。
对象(Object)归属节点(Node)
要确定某个对象归属哪个节点,只需从该对象开始,沿着哈希环顺时针方向查找,找到距离最近的节点,Object A/B/C/D 分别映射至 Node A/B/C/D。
删除节点
现实场景:服务器缩容时删除节点,或者有节点宕机。
要删除节点 Node C:只会影响Object C,,调整映射至欲删除节点的下一个节点 Node D。
增加节点
现实场景:服务器扩容时增加节点。比如要在 Node B/C 之间增加节点 Node X:
只会影响Object C,调整映射至新增的节点 Node X。

虚拟节点
节点数越少,越容易出现节点在哈希环上的分布不均匀,导致各节点映射的对象数量严重不均衡(数据倾斜);相反,节点数越多越密集,数据在哈希环上的分布就越均匀。 但实际部署的物理节点有限,我们可以用有限的物理节点,虚拟出足够多的虚拟节点(Virtual Node),最终达到数据在哈希环上均匀分布的效果
如下图,实际只部署了2个节点 Node A/B,每个节点都复制成3倍,结果看上去是部署了6个节点。
可以想象,当复制倍数为 $2^32$ 时,就达到绝对的均匀,通常可取复制倍数为32或更高。
虚拟节点哈希值的计算方法调整为:对“节点的IP(或机器名)+虚拟节点的序号(1~N)”作哈希。
案例演示
1 | public class ConsistentHashing { |
岛问题

单线程环境
思路:
从i行j列位置出发,向上下左右四个位置依次去感染
1 | public class Islands { |
多线程环境
进阶问题:给你多个CPU,设计出并行算法解决 提示:并查集思想
若是两个CPU情况,分成两部分,记录每个部分的岛屿数量和边界点,对于边界点采用并查集合并,合并同时数量减少。

两个CPU分别处理会得到4个岛,但事实上只有一个岛,原本连通的被割断了,所以需要合并操作



多个CPU:收集四个边界信息,使用并查集

并查集
并查集操作
调用两操作总次数超过 $O(N)$,单词调用操作平均时间复杂度为 $O(1)$
1 | boolean isSameSet(int a, int b); // 查询a和b是否属于一个集合 |
并查集的初始化
并查集由一群集合构成,最开始所有元素单独构成一个集合
当集合中只有一个元素时,其父亲节点指向自身
使用
fatherMap保存并查集中元素的父亲节点,(key,value)表示key节点的father是valuerank是父亲节点所在集合的秩,表示该集合有多少元素,所有节点的rank信息保存在rankMap中
查找父亲节点
要查一个节点属于哪个集合,就是差其代表节点(父亲节点root)
一个节点通过 father 信息逐渐找到最上面的节点,该节点的 father 是自身,则为代表节点
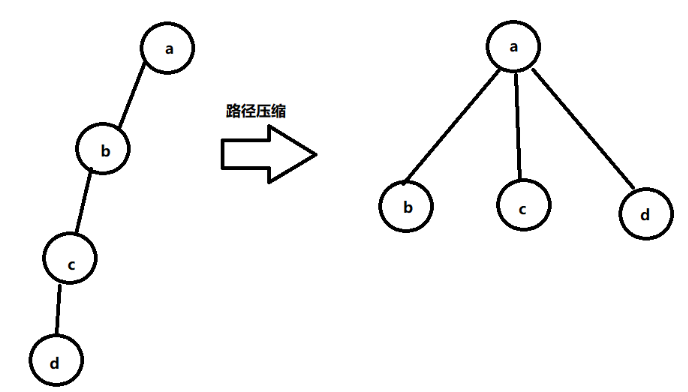
路径压缩
通过 father 找到最上层节点后,会把最上层节点到该节点路径上的所有节点的 father 都设置成最上层节点
合并操作
并查集的合并操作是找到两个集合的代表节点,然后规定将小集合归并到大集合中
算法实现
并查集结构
1 | public class UnionFind { |








